How we used TextRazor’s NLP AI to save our client money and time

Data has never been more business-critical nor more plentiful than it is today. Indeed, many organisations we meet are overwhelmed with information and need help developing smarter, more efficient ways to manage, classify and use their data for most significant effect.
This was the case for a recent client who’s staff were creating bespoke reports for customers by manually searching, classifying and synthesising digital articles and alerts from multiple data streams. Rightly, the client felt that this process was neither scalable nor efficient, and so wanted to automate as much of the searching and classification process as possible, freeing staff to spend more time creating quality reports.
The brief
As we proceeded through the first step of our process – the strategy & research phase – it became clear that the client required a powerful and nuanced solution to text search and classification. In short, the technology had to be able to do the job as well as (if not better than) a human, which ruled out a dumb (but simple to implement) keyword filtering approach early on.
As a result, we turned to the world of artificial intelligence (AI) based natural language processing (NLP), which offered a far more powerful approach to sifting meaning from long-form text articles.
What is natural language processing?
NLP is a branch of machine learning that seeks to allow computers to read and understand written language, which is a complex, unstructured data set that isn’t easy for computers to parse.
Take the following sentence:
“Hazard was on fire last night; he destroyed the Brighton defence.”
It’s simple enough for a human to understand that the sentence probably relates to a sports match where a player called Eden Hazard played well and helped his team beat Brighton.
However, for a computer-based AI, the sentence poses some problems. For example, it needs to know Hazard is a person, not a literal hazard, and it needs to understand that being on fire is a colloquialism for performing well. If it didn’t know this, a computer could, in all likelihood, conclude that something hazardous in the Brighton area was on fire last night and as a consequence, the city’s defensive structures were destroyed.
As you can imagine, these kinds of subtleties are essential if you’re trying to use AI to classify the topic, content or sentiment of a piece of text. Should this sentence be classified as related to sports, or disasters, or maybe both if you’re a Brighton fan?
How TextRazor NLP works
To add natural language processing to the portal, we partnered with TextRazor, a specialist, London based machine learning NLP platform.
The TextRazor platform receives text articles or documents (also called records) via an API, examines them, and returns a list of entities (i.e. people, places, etc.) featured in the text, relations between these entities, and a list of graded document classifications.
This is all achieved through what’s termed an ‘ensemble approach’ whereby the platform builds its understanding of the document by analysing it with numerous techniques, from deep learning based neural networks to simpler linear models and rules.
![]()
Under the AI hood
First, entities are identified; a relatively simple step. For instance, the use of ‘Mr’ before a word usually denotes a man, and the word corporation after a capitalised word would usually indicate a company.
After that, the more complex work of disambiguation and entity linking takes place. This is the area that is most proprietary to each NLP platform, with each using its own approach and AI algorithms. Here, the platform makes contextual links between the entities in the record based on the words used and what the system already knows about the entities from prior training.
We’d expected this machine learning training process to be an ongoing one, with each new document processed adding to the platform’s understanding. However, during a recent chat with Toby Crayston, Founder of TextRazor, he explained that this isn’t the case, as many of the records that the algorithm examines contain sensitive client information. Instead, the TextRazor AI is trained using a custom dataset incorporating sources like Wikipedia, web pages, and social data, with updates and improvements made by engineers on an ongoing basis using the latest academic NLP research.
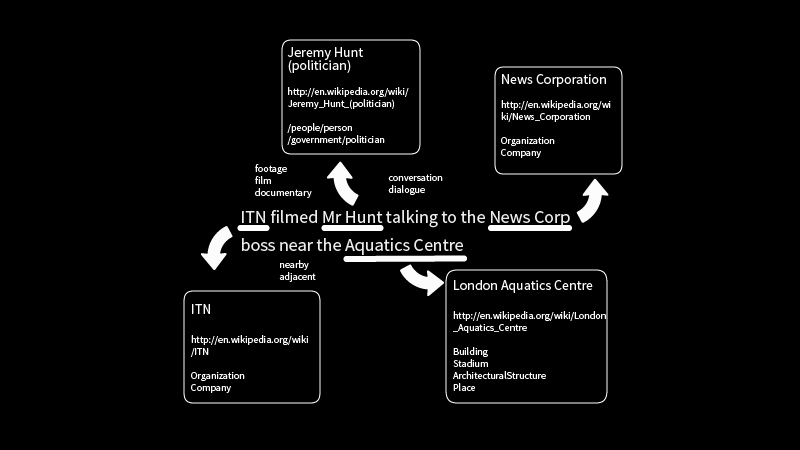
With disambiguation completed, the platform ‘understands’ the document, meaning topic tagging and classification can take place. By default, classification is done using the media industry standard IPTC News codes and IAB categories, with each record given a score between zero and one to say how relevant the content is to each class.
The data is then packaged up and sent back to the client who supplied the source document. All of this processing takes places inside of a second.
In fact, Crayston highlighted that latency and downtime are one of the platform’s biggest threats. “Our technology is often part of the critical path for our customer’s operations, meaning that if we go down – or even slow down – so do they.”
Is there any NLP specific hardware?
To keep everything running smoothly, TextRazor uses a mix of dedicated servers and Amazon EC2 instances that can be spooled up at short notice if demand spikes. “All the hardware is pretty standard,” says Crayston, “The processing is pretty intensive, but we don’t use any specialist hardware. The tens of millions of records we process a day all go through standard server CPUs.”
If you’d like to read more about the intricacies of NLP, the TextRazor blog is well worth a read.
The power of custom classification in NLP
The IPTC News codes and IAB codes that TextRazor uses for classification are useful. However, one of the most powerful features of the platform, particularly for our client, is being able to define custom classifications. This process leverages the vast web of entity linkages and semantic understanding already present within the platform.
Custom classifications are easy to set up – give the platform a few keywords, and the AI will build an understanding of the classification based on linkages it made during its training. Let’s use an example close to our heart; breakfast.
If we created a new classification with the single keyword of ‘breakfast’, the system would start assessing how closely records linked to that concept. As part of this process, the platform looks for simple keyword matches, but also, importantly, for links between things it already knows are related to breakfast in some way. So a simple mention of eggs may not give a high rating, but an article that mentions eggs alongside bacon, cereal, pancakes, the morning and coffee, would score highly.

This is, of course, a daft example, but this feature was particularly vital for our client as it allowed records to be classified against novel concepts intelligently, based on natural language linkages.
Implementing the TextRazor API
Our client’s system pulls in and organises records from multiple sources with high throughput. This pushed us to be thoughtful about where within the data pipeline we integrated the call to the TextRazor API, as we needed to avoid any potential loss of connection blocking other data processing steps that the platform takes.
To this end we built the system to operate asynchronously – as soon as a record has been obtained, it’s available to the end user on the platform immediately. At the same time, the platform independently queues up requests to other services, such as TextRazor. A response to this request could return within seconds, or in several hours (thankfully, usually the former) and at this point, we augment the platform record with the new information.
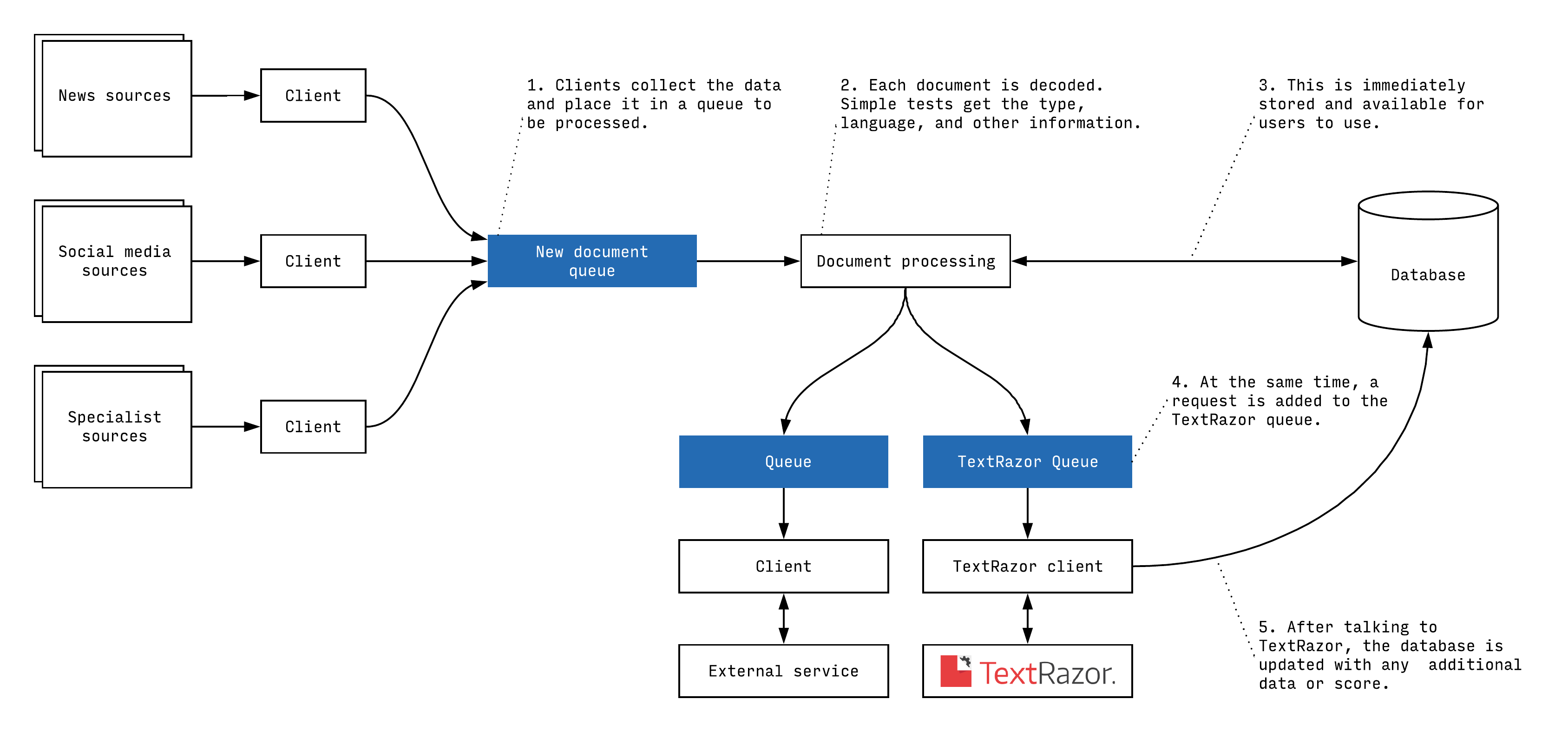
These queue steps are critical, as they allow us to isolate time-critical processes from those that could impose some delay, meaning the platform is more reliable.
The data details
When we call out to the API, we merely give TextRazor the record we need analysing and any custom classifiers (set up in advance) that we’d like the system to classify the content against. TextRazor will then return with a structured (JSON) response that includes a breakdown of each classification and its confidence in each one.
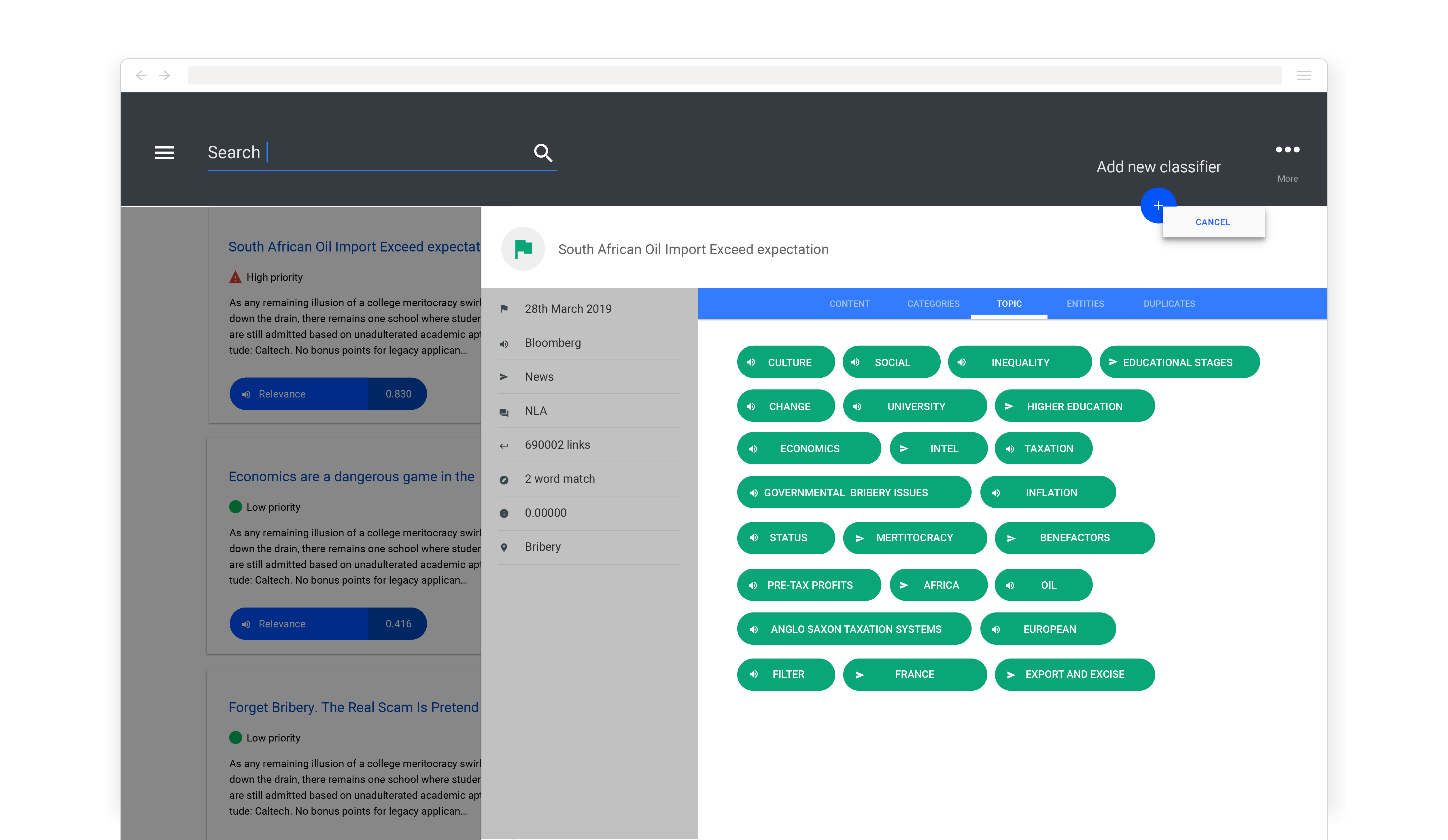
These confidence scores are then included as a component in some additional proprietary calculations we’ve built into the system, which involve other signals too – such as the historical reliability of the source. The result is a score that is surfaced to users within the platform, grading the importance of the item.
Cleaning the data
Many published news articles are syndicated to multiple sources, so to save the client time and resource we wanted to avoid pushing the same content to TextRazor more than once.
To do this, we use Elasticsearch to compare each article’s content with those the platform has already seen. Where the similarity of the content is above a set threshold, the system skips sending it to TextRazor, instead, marking it as a duplicate. The number of copies for a given article can then also be used as a signal of the significance of the information.
UX design challenges
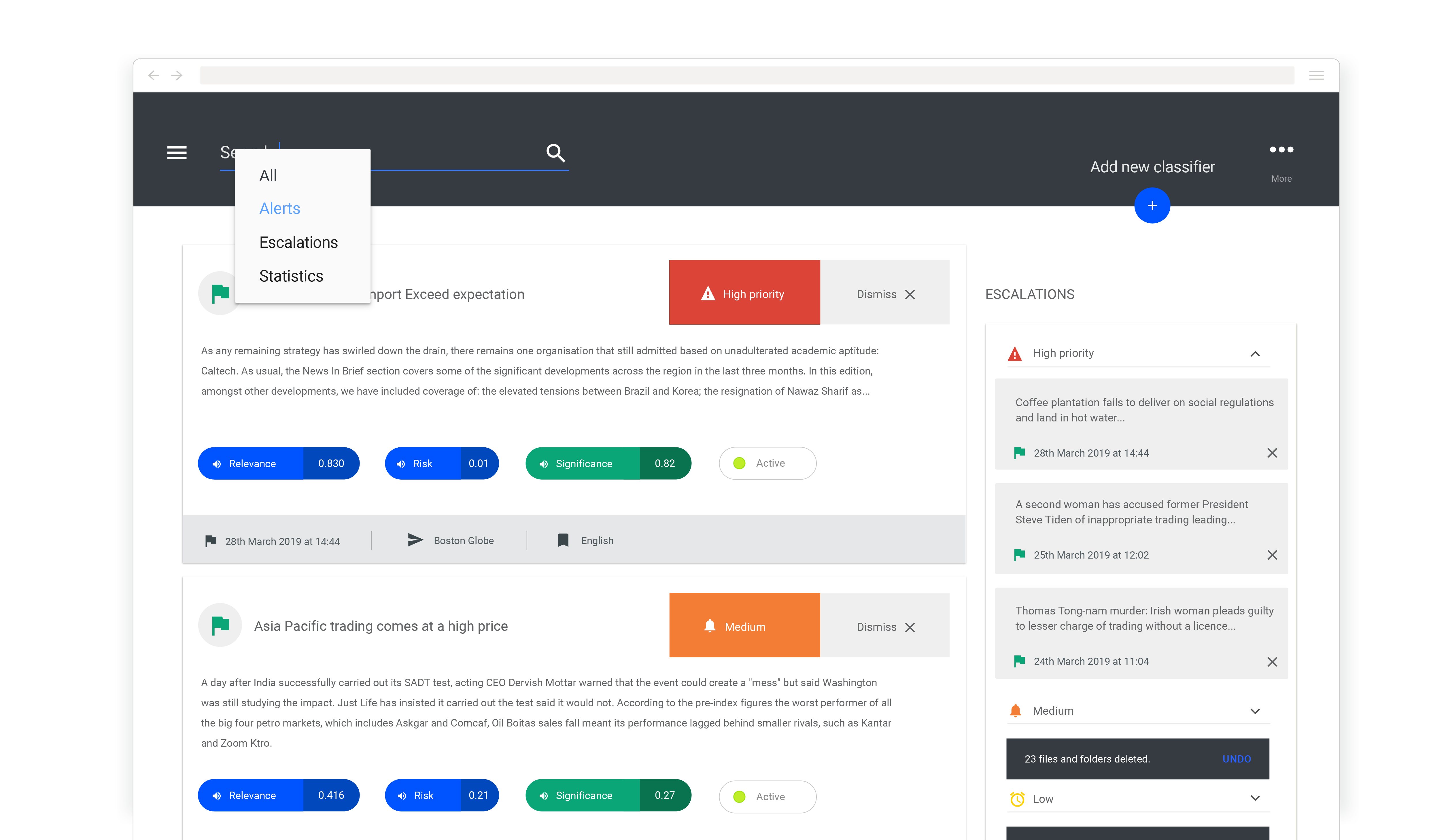
The TextRazor API is only one of the myriad sources that feed into the portal – indeed, the platform pulls in an almost overwhelming amount of information. Consequently, we needed to work closely with end users of the platform to make sure our UX design was distilling this avalanche of data into only the clearest, most relevant and actionable gradings of importance.
Making the grade
To achieve this, we chose to aggregate all of the different signals into a consistent set of low, medium, and high importance gradings for each record. This involved implementing a system that allows our client to adjust how the ratings are computed, by way of a few mathematical formulas that can be updated without re-deploying the platform. In addition, each custom classifier can have its thresholds for low, medium, and high gradings adjusted independently, giving the client fine grain control over how the platform displays information.
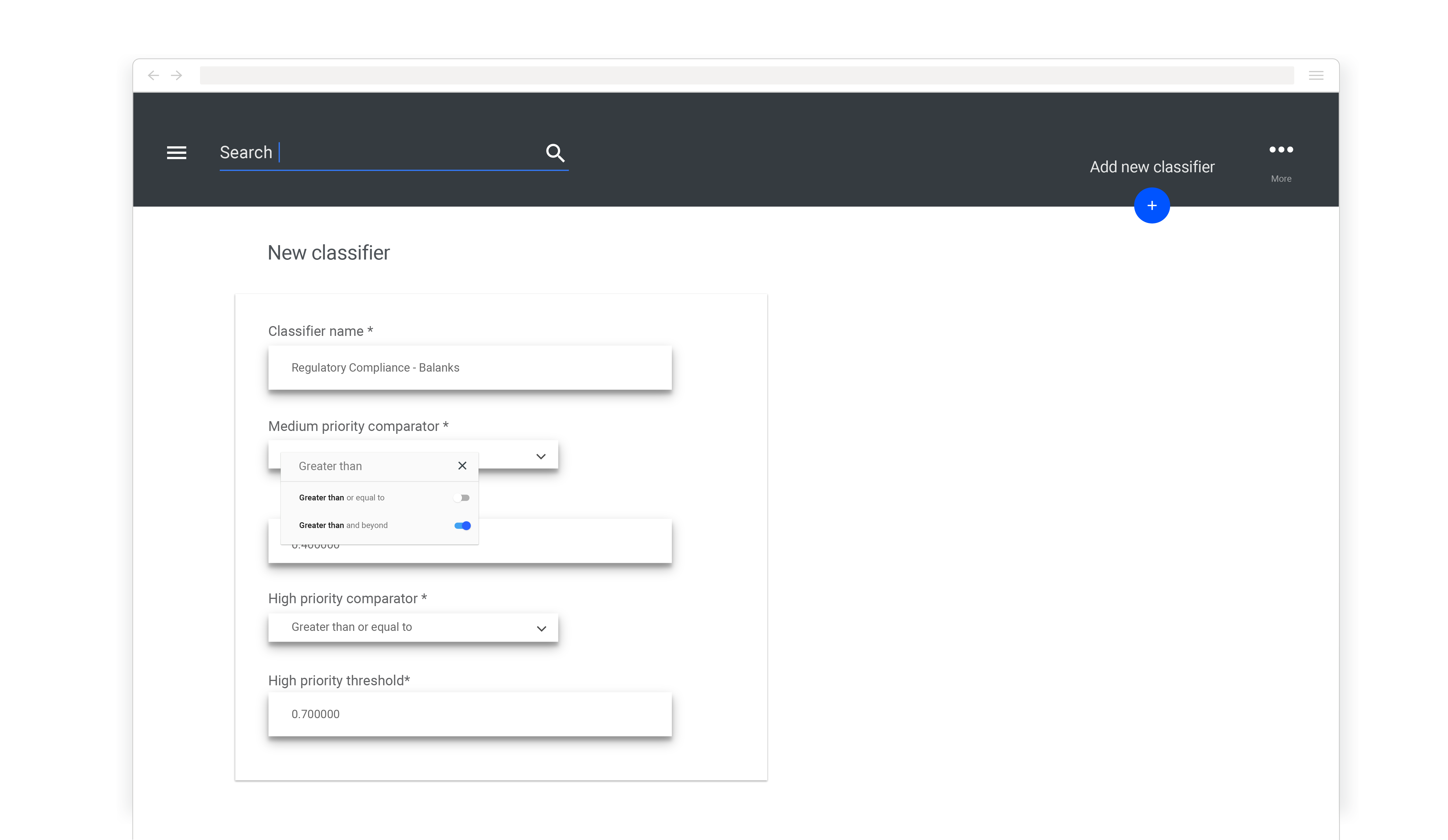
With this structure in place, the platform can provide quick-glance gradings of records based on multiple inputs, but also, should an analyst require, expand the item to show the constituent signals. To make user’s work more manageable, we also added tools to quickly filter and dismiss batches of news items based on these gradings.
The shopping cart approach
A further significant component of designing the user-flows and UX in this part of the system was how to take articles of note and forward them on to be reviewed. Important records need to be grouped and moved through a review process to present a single curated “alert” that could be based on several corroborating sources.
After mapping out the expected workflows with the client and end users, we quickly realised that this sort of process already existed in another, widespread, class of software; e-commerce systems. After user testing, we ultimately settled on a shopping cart and checkout style interface where reviewers would select multiple articles into a ‘cart’, and escalate them to senior researchers via a simplified multi-user ‘checkout’ style process.
The outcomes
Integrating the TextRazor NLP platform into our client’s internal report portal delivered tangible business value to our customer in multiple ways.
Saving our client time
Firstly, and most obviously, the platform integration saved the client’s workforce time by intelligently classifying documents more quickly than dumb keyword filters and humans had been able to do previously.
TextRazor’s AI-based NLP processing assesses how relevant records are too specific concepts rapidly, meaning only the most pertinent articles get flagged to analysts. This saves analysts time sorting through articles, so they spend more time creating valuable reports for paying clients. This efficiency saving has allowed our client to grow their turnover without increasing headcount.
Enabling users to do better work
Secondly, bringing the power of NLP and custom concepts to the reporting platform has allowed our client to create and sell increasingly complex reports in more areas, opening up new business streams for the company and allowing them to position themselves as the market leader in their field.
Whereas previously new concept filters and report topics were complex and time-consuming to create and manually troubleshoot, they are now quick and straightforward to add. TextRazor’s underlying web of entity linkages and semantic understanding means new topic classifications can be set up with as little as one keyword, with the platform now doing the job of identifying linked concepts and surfacing records that relate to them automatically.
To conclude
We believe this project study demonstrates how the power of natural language processing – especially when combined with a flexible search platform like Elasticsearch – can extract real business value from the mountains of text-based data modern organisations are faced with.
However, we hope we’ve also shown that it’s not enough to just toss new tech into a business and expect great outcomes by default. All technologies, however new or flashy, always need to be integrated and rolled out in a way that is sympathetic to the end users that will be interacting with them.
We’re proud of the technical work we’ve done for the client as part of this project, but as ever, effective UX and UI research, design and end-user testing were vital to making sure that the business could realise the potential of the new technology.
Photo by Cullan Smith on Unsplash